作者:君哥哥 | 来源:互联网 | 2023-06-26 23:09
篇首语:本文由编程笔记#小编为大家整理,主要介绍了强化学习从PG到PPO(基于百度飞桨PaddlePaddle+PARL)相关的知识,希望对你有一定的参考价值。前段时间抽
篇首语:本文由编程笔记#小编为大家整理,主要介绍了强化学习从PG到PPO(基于百度飞桨PaddlePaddle+PARL)相关的知识,希望对你有一定的参考价值。
前段时间抽空学习了《百度强化学习基础课程》强化学习7日打卡营-世界冠军带你从零实践,总共七天的视频+线上作业(视频地址:世界冠军带你从零实践强化学习),让我这个小白基本对于强化学习有了简单的理解,知识虽然是灌进脑袋里,但仍是一团浆糊,好记性不如烂笔头,后续会多写笔记整理下自己的对于课程所学的理解、思考和发散,今天先从最简单的PG算法开始,然后到最近刚有了解的PPO算法。
PG算法原理
PG算法即是基于策略(Policy-based),不同于Value-based的算法的Q函数,其是直接优化策略函函数,在深度强化学习中,其一般是采用神经网络拟合策略函数π(s,a),而优化的目标是策略函数的期望回报,即所有策略路径同策略路径发生概率p的加权和,当迭代次数足够的情况,可以用所有迭代的策略路径回报的平均值来表示。
在paddle中使用PG是非常简单的,通过如下调用PG算法
from parl.algorithms import PolicyGradient
然后可以用paddle创建一个简单的模型。
class Model(parl.Model):
def __init__(self, act_dim):
act_dim = act_dim
hid1_size = act_dim * 10
self.fc1 = layers.fc(size=hid1_size, act='tanh')
self.fc2 = layers.fc(size=act_dim, act='softmax')
def forward(self, obs): # 可直接用 model = Model(5); model(obs)调用
out = self.fc1(obs)
out = self.fc2(out)
return out
之后定义Agent,然后按如下就能完成PG框架的配置~
# 根据parl框架构建agent
model = Model(act_dim=act_dim)
alg = PolicyGradient(model, lr=LEARNING_RATE)
agent = Agent(alg, obs_dim=obs_dim, act_dim=act_dim)
回到PPO的实现
PPO论文地址:https://arxiv.org/abs/1707.06347
对于PG算法来说,最大的问题是在策略参数更新后,还要需要重新使用同环境互动收集数据再进行下一轮迭代,PPO算法是利用了重要性采样的思想,在不知道策略路径的概率p情况下,通过模拟一个近似的q分布,只要p同q分布不差得太远,通过多轮迭代可以快速参数收敛。
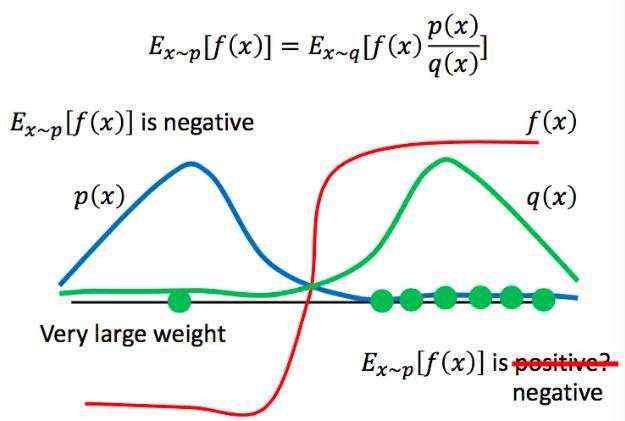
如何去实现这个重要性采样呢?PPO结合AC框架, agent由两部分组成,Actor负责与环境互动收集样本,等同于原来PG的情况,其更新即PPO梯度的更新,添加了Critic,负责评判actor的动作好坏,实际上就是重要性采样了。
class Model(parl.Model):
def __init__(self, act_dim):
self.actor_model = ActorModel(act_dim)
self.critic_model = CriticModel()
def policy(self, obs):
return self.actor_model.policy(obs)
def value(self, obs, act):
return self.critic_model.value(obs, act)
def get_actor_params(self):
return self.actor_model.parameters()
class ActorModel(parl.Model):
def __init__(self, act_dim):
hid_size = 100
self.fc1 = layers.fc(size=hid_size, act='relu')
self.fc2 = layers.fc(size=act_dim, act='tanh')
def policy(self, obs):
hid = self.fc1(obs)
means = self.fc2(hid)
return means
class CriticModel(parl.Model):
def __init__(self):
hid_size = 100
self.fc1 = layers.fc(size=hid_size, act='relu')
self.fc2 = layers.fc(size=1, act=None)
def value(self, obs, act):
concat = layers.concat([obs, act], axis=1)
hid = self.fc1(concat)
Q = self.fc2(hid)
Q = layers.squeeze(Q, axes=[1])
return Q
完成了模型的设置,在算法上重点在于如下两个模型的学习更新参数(在parl可以直接调用)
Actor模型优化的LOSS,其中KL是参数是描述新旧π(s,a)的相似程度的散度
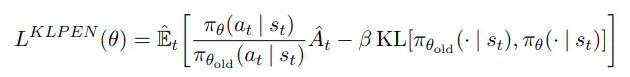
Critic模型优化的LOSS
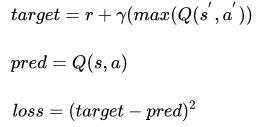
具体代码如下:
def Actor_learn(self, obs, actions, reward, beta=None):
"""
"""
# 之前策略函数q
old_means, old_logvars = self.old_policy_model.policy(obs)
old_means.stop_gradient = True
old_logvars.stop_gradient = True
# 给定均值及方差,计算actions的log概率函数
old_logprob = self._calc_logprob(actions, old_means, old_logvars)
# 现在的策略函数p
means, logvars = self.model.policy(obs)
logprob = self._calc_logprob(actions, means, logvars)
# 新旧策略函数p及q的KL散度
kl = self._calc_kl(means, logvars, old_means, old_logvars)
kl = layers.reduce_mean(kl)
# 以下对应于PPO参数更新LOSS
loss1 = - layers.reduce_mean(reward * layers.exp(logprob - old_logprob))
loss2 = kl * beta
loss = loss1 + loss2
optimizer = fluid.optimizer.AdamOptimizer(self.policy_lr)
optimizer.minimize(loss)
return loss, kl
def Critic_learn(self, obs, val):
"""
"""
predict_val = self.model.value(obs)
# LOSS
loss = layers.square_error_cost(predict_val, val)
loss = layers.reduce_mean(loss)
optimizer = fluid.optimizer.AdamOptimizer(self.value_lr)
optimizer.minimize(loss)
return loss
在运行时可以先用一个简单的环境跑下程序,看看能否跑通,训练时参数能否收敛~
from gridworld import FrozenLakeWapper
env = gym.make("FrozenLake-v0", is_slippery=False) # 0 left, 1 down, 2 right, 3 up
#env = gym.make("CliffWalking-v0") # 0 up, 1 right, 2 down, 3 left
env = FrozenLakeWapper(env)
这里非常推荐大家使用parl例子的里gridword.py文件https://github.com/PaddlePaddle/PARL/blob/develop/examples/tutorials/lesson1/gridworld.py,可以直接渲染出运行环境

最后再吹一拨parl,其里面已经集群了算法和例子,调用起来非常方便~,另外还可以上百度飞桨平台https://aistudio.baidu.com/,里面有许多深度学习的课程。








 京公网安备 11010802041100号
京公网安备 11010802041100号